01终端侧生成式AI如何演进
产品:14(8GB/256GB) 小米 手机
生成式AI时代已经到来。生成式AI创新正在持续快速发展,并逐步融入人们的日常生活,为用户提供增强的体验、提高生产力和带来全新的娱乐形式。那么,接下来会发生什么呢?本文将探讨即将到来的生成式AI趋势、正在赋能边缘侧生成式AI的技术进步和通向具身机器人之路。我们还将阐述高通技术公司的端到端系统理念如何处在赋能下一轮终端侧创新方面的行业最前沿。
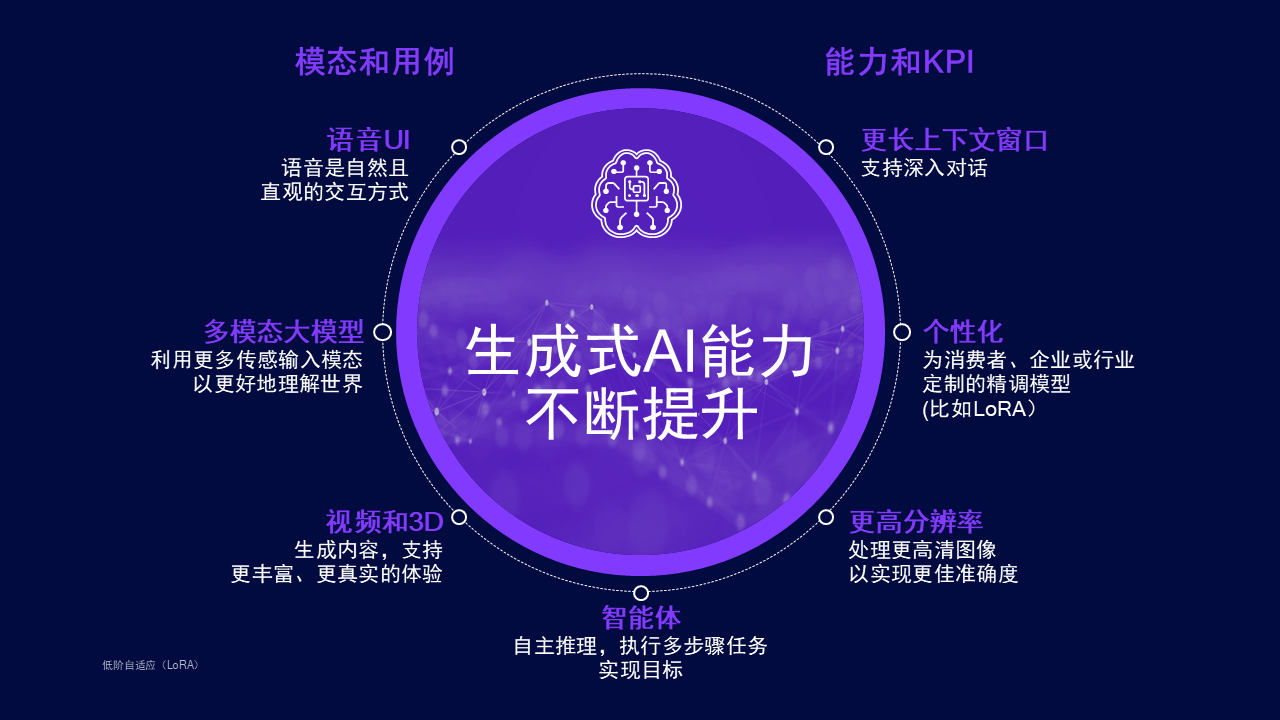
生成式AI能力正在持续多维度提升
即将到来的趋势和终端侧AI的重要性
Transformer因其可扩展性,已成为主要的生成式AI架构。随着技术的不断演进,Transformer正在从传统的文本和语言处理扩展到更多模态,带来了全新能力。我们正在多个领域看到这一趋势,比如在汽车行业,通过多摄像头和激光雷达(LiDAR)的协同实现鸟瞰视角;在无线通信领域,利用Transformer结合全球定位系统(GPS)、摄像头和毫米波(mmWave)信号,以优化毫米波波束管理。
另一个主要趋势是生成式AI的能力在这两方面持续增强:
模态和用例
能力和KPI
在模态和用例方面,我们看到了语音UI、多模态大模型(LMM)、智能体、视频/3D的提升。在能力和KPI方面,我们看到了更长上下文窗口、个性化和更高分辨率的提升。
为了充分实现生成式AI的全部潜能,将这些趋势能力引入边缘侧终端对于实现时延改善、交互泛化和隐私增强至关重要。例如,赋能具身机器人与环境和人类实时交互,这就需要利用终端侧处理确保即时性和可扩展性。
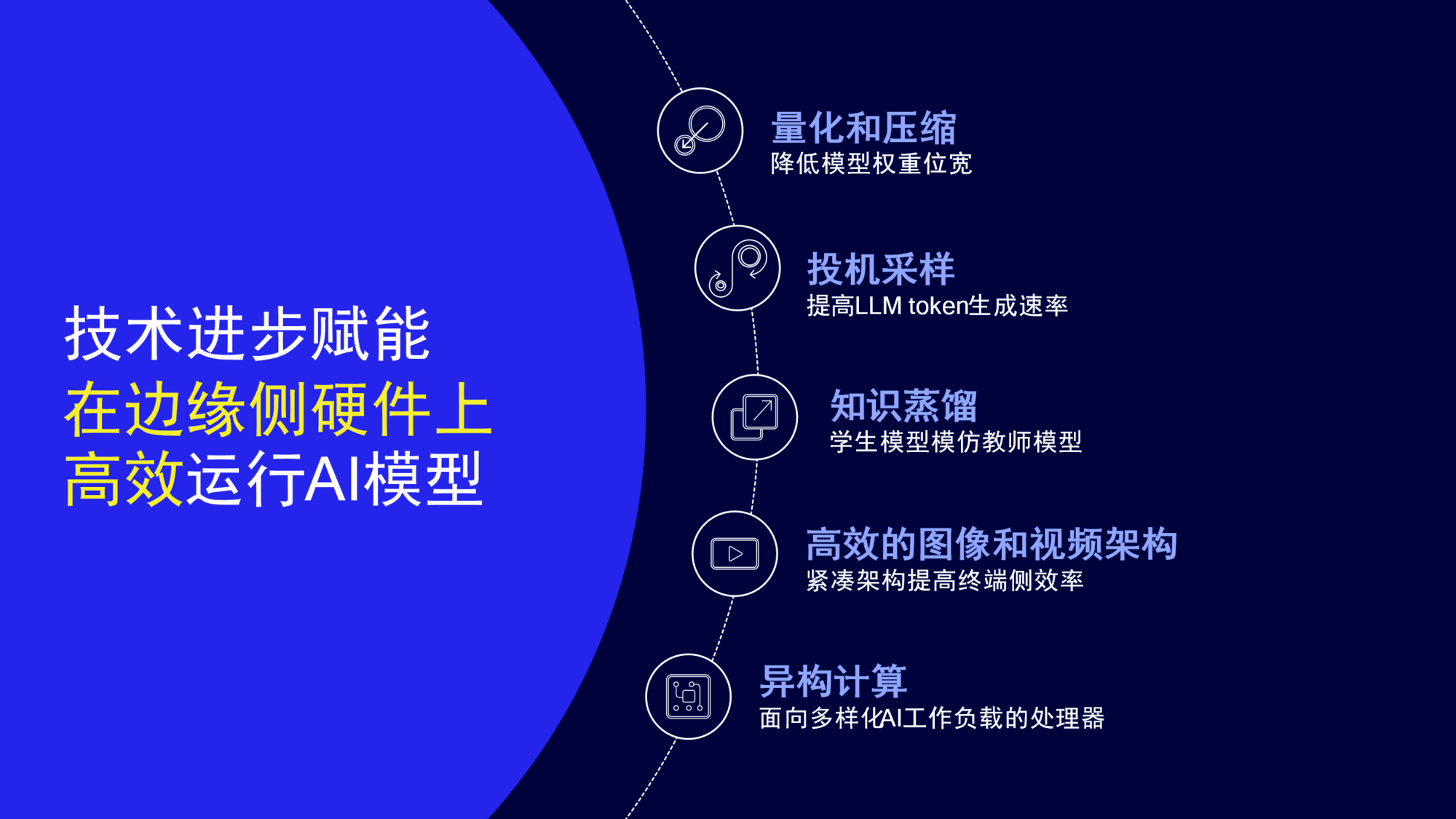
我们正在通过多种技术优化模型,赋能高效终端侧AI
面向生成式AI的边缘平台技术进步
我们如何将更多生成式AI能力引入边缘终端呢?通过多维度技术研究,高通将全面推进面向生成式AI的边缘平台发展。
我们致力于通过知识蒸馏、量化、投机采样高效的图像和视频架构,以及异构计算等技术优化生成式AI模型,使其能够在硬件上高效运行。这些技术相辅相成,因此对从多角度解决模型优化和效率挑战至关重要。
以大语言模型(LLM)的量化为例。大语言模型通常以16比特浮点进行训练。我们希望在保持准确度的同时压缩大语言模型,以提高性能。例如,将16比特浮点(FP16)模型压缩为4位整数(INT4)模型,能够将模型缩小4倍,同时降低内存带宽占用、存储、时延和功耗。
量化感知训练结合知识蒸馏有助于实现准确的4位大语言模型,但如果需要甚至更低的bits-per-value指标,向量量化(VQ)可帮助解决该问题。向量量化在保持期望准确度的同时,进一步压缩模型大小。我们的向量量化方法能以INT4线性量化的相似精确性,实现3.125bits-per-value,实现甚至更大的模型能够在边缘终端的DRAM限制内运行。
另一个例子是高效视频架构。高通正在开发让面向终端侧AI的视频生成方法更高效的技术。例如,我们对视频到视频生成式AI技术FAIRY进行了优化。在FAIRY第一阶段,从锚定帧提取状态。在第二阶段,跨剩余帧编辑视频。优化示例包括:跨帧优化、高效instructPix2Pix和图像/文本引导调节。
通向具身机器人之路
高通已经将生成式AI的相关工作扩展到大语言模型及其相关用例研究,尤其是面向多模态大模型(LMM)集成视觉和推理。去年,我们在2023年国际计算机视觉与模式识别会议(CVPR2023)上进行了支持基于实时视觉大语言模型的健身教练技术演示,我们在近期还探索了多模态大模型针对更复杂的视觉问题进行推理的能力。在此过程中,我们在存在运动和遮挡的情况下推断物体位置方面取得了行业领先技术成果。
然而,与情景式智能体进行开放式、异步交互是一项亟待解决的挑战。目前,大多数面向多模态大模型的解决方案只具备以下基本能力:
仅限于离线文档或图像的基于回合的交互。
仅限于在视觉问答式(VQA)对话中进行现实的快速抓拍。
我们在情景式多模态大模型方面取得了一些进展,这些模型能够实时处理直播视频流,并与用户进行动态交互。其中一项关键创新是针对情景式视觉理解的端到端训练,这将开辟通向具身机器人之路。
未来将有更多终端侧生成式AI技术进步
高通的端到端系统理念处于推动边缘侧生成式AI下一轮创新的行业最前沿。我们持续进行研究,并将新技术和优化快速引入商用产品。我们期待看到AI生态系统如何利用这些新能力,让AI无处不在,并提供更佳体验。