上海/维也纳,2024年7月23日— 在YandexResearch、ISTAustria、NeuralMagic和KAUST的共同努力下,两种创新的大型语言模型(LLM)压缩方法——加性量化语言模型(AdditiveQuantization for Language Models,AQLM)和PV-Tuning正式发布。这两种方法可以将模型大小减少多达8倍,同时保留95%的响应质量。这项研究成果已经于正在维也纳举行的国际机器学习会议(InternationalConference on Machine Learning, ICML)上展示。
AQLM和PV-Tuning的关键特点
AQLM:利用传统用于信息检索的加性量化方法进行LLM压缩。即使在极限压缩下,该方法也能保持甚至提高模型的准确性,使LLM能够在家用计算机等日常设备上运行,从而显著减少内存消耗。
PV-Tuning:解决模型压缩过程中可能出现的误差问题。当AQLM和PV-Tuning结合使用时,可以实现最佳效果——紧凑的模型即使在有限的计算资源上也能提供高质量的响应。
方法评估和认可
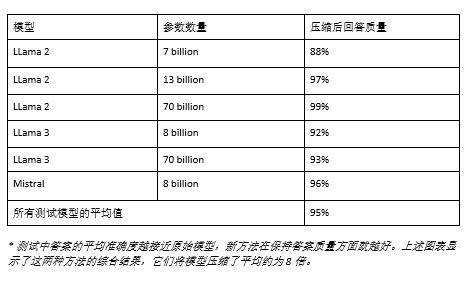
这些方法的有效性通过对流行的开源模型如LLama2、Mistral和Mixtral的严格评估得到了验证。研究人员压缩了这些大型语言模型,并根据英语基准测试WikiText2和C4评估了答案质量。即使模型被压缩了8倍,它们的答案质量仍保持在令人印象深刻的95%。
AQLM和PV-Tuning的受惠者
新方法为开发和部署专有语言模型和开源LLM的公司提供了巨大的资源节约。例如,压缩后的130亿参数的Llama2模型只需1个GPU即可运行,相比之下,原模型需要4个GPU,从而使硬件成本降低最高达8倍。此举使得初创公司、个人研究者和LLM爱好者能够在他们的日常计算机上运行先进的LLM,譬如Llama。
探索新的LLM应用
AQLM和PV-Tuning使得在计算资源有限的设备上离线部署模型成为可能,为智能手机、智能音箱及更多设备开辟了新的使用场景。用户可以在这些设备上使用文本和图像生成、语音助手、个性化推荐甚至实时语言翻译等功能,而无需联网。
此外,使用这些方法压缩的模型能够以快达4倍的速度运行,因为它们需要的计算量减少了。
实施和访问
全球的开发人员和研究人员现在可以在GitHub上使用AQLM和PV-Tuning。作者提供的演示材料为有效训练各种应用的压缩LLM提供了指导。此外,开发人员还可以下载已经使用这些方法压缩的流行开源模型。
ICML亮点
Ascientific article by Yandex Research on the AQLM compression methodhas
YandexResearch关于AQLM压缩方法的科学文章已在ICML上发表,这是世界上最负盛名的机器学习会议之一。与ISTAustria和AI初创公司NeuralMagic的研究人员共同撰写的这篇论文标志着LLM压缩技术的重大进步。
关于Yandex:
Yandex是一家全球技术公司,致力于构建由机器学习驱动的智能产品和服务。公司旨在帮助消费者和企业更好地在线上和线下世界中导航。自1997年以来,Yandex一直提供世界级的、本地相关的搜索和信息服务,并开发了市场领先的按需交通服务、导航产品和其他移动应用,服务于全球数百万消费者。
编者按
部署大型语言模型(LLM)在消费级硬件上是一个巨大的挑战,因为模型大小和计算效率之间存在固有的权衡。量化等压缩方法提供了部分解决方案,但通常会牺牲模型性能。
为应对这一挑战,YandexResearch、ISTAustria、KAUST和NeuralMagic的研究人员开发了两种压缩方法——加性量化语言模型(AQLM)和PV-Tuning。AQLM将每个模型参数的位数减少到2- 3位,同时在极限压缩场景下保持甚至增强模型准确性。PV-Tuning是一种表示无关的框架(arepresentation-agnostic framework),它概括并改进了现有的微调策略。
AQLM的关键创新包括对权重矩阵的学习加性量化,适应输入变异性,并在层块之间联合优化代码簿参数。这一双重策略使AQLM在压缩技术领域设立了新的基准。
AQLM的实用性通过其在GPU和CPU架构上的实现得到了验证,使其适用于现实应用。比较分析显示,AQLM可以在不影响模型性能的情况下实现极限压缩,如其在零样本任务中的模型困惑度和准确性指标上显示的优异结果所示。
PV-Tuning在受限情况下提供了收敛保证(convergenceguarantees),并且在高性能模型(如Llama和Mistral)的1-2位向量量化中优于以前的方法。通过利用PV-Tuning,研究人员实现了第一个针对Llama2模型的2位参数的帕累托最优量化。
这些方法的有效性通过对流行的开源模型如LLama2、Mistral和Mixtral的严格评估得到了验证。研究人员压缩了这些大型语言模型,并根据英语基准测试WikiText2和C4评估了答案质量。即使模型被压缩了8倍,它们的答案质量仍保持在令人印象深刻的95%。

本文属于原创文章,如若转载,请注明来源:Yandex研究人员推出AQLM和PV-Tuning,模型体积缩小8倍,质量保留95%https://mobile.zol.com.cn/886/8865820.html